

Existen muchas definiciones de Inteligencia Artificial (IA). La más formal es atribuida a Martin Minsky, que en sus palabras la definió como “la ciencia de hacer que las máquinas hagan cosas que requerirían inteligencia si las hubiera hecho un humano”. Esta definición nos obliga a observar lo que significa ‘inteligencia’, para lo que, sorprendentemente, no tenemos una definición unívoca. Sin embargo, podemos diferenciar diferentes aspectos de ésta: uso del lenguaje, razonamiento, percepción, cómputo, aprendizaje, etc. e incluso el aspecto conocido como inteligencia emocional.
Hasta hace relativamente poco las máquinas tenían poca destreza en muchos de estos aspectos de la inteligencia, a excepción de los puramente computacionales. En los últimos años hemos asistido a una explosión de uso y adopción de la IA motivada por el éxito en la implementación y despliegue del machine learning (aprendizaje automático) especialmente en su faceta de deep learning (aprendizaje profundo).
Hasta hace relativamente poco las máquinas tenían poca destreza en muchos de estos aspectos de la inteligencia, a excepción de los puramente computacionales
El aprendizaje automático es un subconjunto de la Inteligencia Artificial, y a su vez el aprendizaje profundo es un subconjunto del aprendizaje automático. Se suele distinguir entre aprendizaje profundo y aprendizaje automático convencional, porque el primero usa redes neuronales artificiales.
Superpotencias en la Inteligencia Artificial
Respecto al despliegue temporal, Kaifu-Lee distingue cuatro fases de adopción de la Inteligencia artificial en su libro ‘AI Superpowers’ (Superpotencias en la Inteligencia Artificial): Internet, Negocios, Percepción y Autonomía.
En la primera fase las protagonistas fueron las empresas nativas de Internet (Google, Facebook, Amazon, etc.)
porque ya habían acumulado datos a escala desde sus inicios. Por eso fueron las que primero incorporaron la IA en sus productos y procesos: a veces para perfeccionar productos existentes (por ejemplo, el buscador de Google ahora utiliza modelos de lenguaje incorporando aprendizaje profundo para obtener resultados más relevantes) o para crear productos o servicios nuevos dentro de esas empresas (por ejemplo, sistema de transcripción de audio a texto que se usa para el dictado en los móviles, dicho sistema no existía antes de usarse Inteligencia Artificial en Google).
Las empresas nativas de Internet (Google, Facebook, Amazon, etc.) fueron las que primero incorporaron la Inteligencia Artificial
Actualmente nos encontramos inmersos en la segunda fase, la de los ‘Negocios’, en la que empresas de todos los sectores comienzan a integrar procesos movidos por motores de Inteligencia Artificial, desde sistemas para optimizar procesos a crear nuevos productos o formas de interaccionar con los clientes más eficaces o eficientes.
En la mayoría de los casos, las fases de ‘Internet’ y ‘Negocios’ usan datos que han sido captados o generados en forma digital o numérica, que es la forma nativa para la ingestión de datos para modelos clásicos de aprendizaje automático.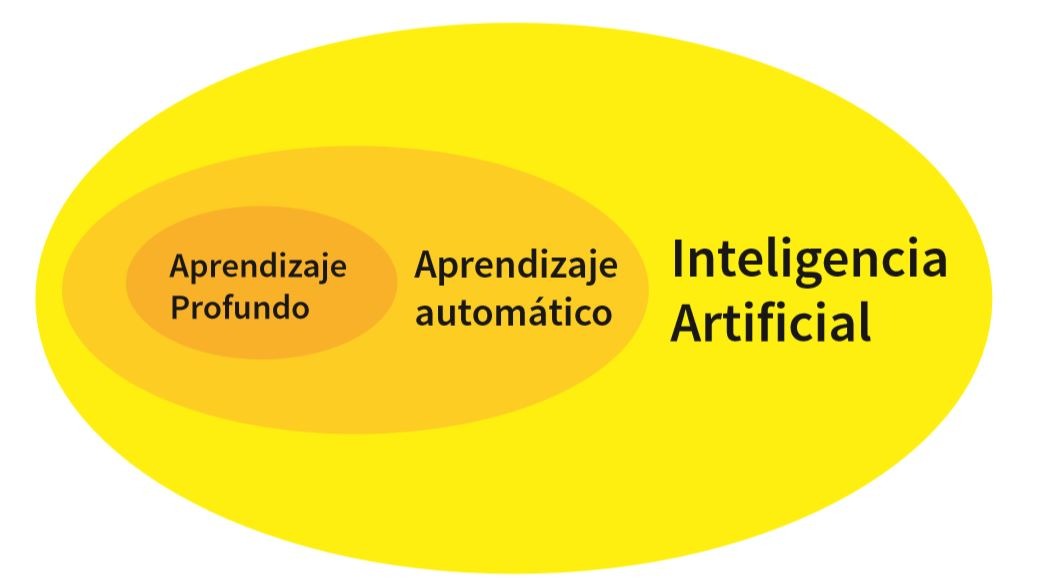
En la tercera fase, de ‘Percepción’, los sistemas de Inteligencia Artificial son capaces de crear representaciones computacionales mediante entradas de datos del mundo físico no procesadas, por ejemplo: imágenes, vídeos y audio. Hasta hace poco este tipo de datos quedaba fuera del alcance de los modelos de IA; sin embargo, desde aproximadamente el año 2012, gracias a los avances en el aprendizaje profundo, es posible resolver problemas de clasificación, detección o segmentación en imágenes, vídeo, audio, etc. haciendo que los sistemas puedan absorber información del mundo físico (mediante cámaras, micrófonos, y otro tipo de sensores).
Si bien con la fase de ‘Percepción’ los sistemas de Inteligencia Artificial son capaces de captar e interpretar (crear modelos computacionales) el entorno físico, en la fase de ‘Autonomía’, apoyada por avances en robótica, se desarrollarán sistemas dotados de movimiento e interacción en el mundo físico: coches autónomos, drones, etc.
Aprendizaje automático supervisado
El aprendizaje automático tiene a su vez múltiples facetas según el sistema que usemos para entrenar los modelos, pero en el mundo de los negocios la modalidad más utilizada es la llamada aprendizaje supervisado (otras modalidades, como, por ejemplo, el aprendizaje no supervisado o el aprendizaje por refuerzo, han sido objeto recientemente de un gran esfuerzo de investigación, pero resultan mucho menos maduras para su despliegue empresarial).
Para entender cómo funciona el aprendizaje supervisado pongamos que dada una entrada X queremos predecir una salida Y. Por ejemplo, la entrada es una imagen y la salida es una clasificación de a qué categoría corresponde dicha imagen (de un conjunto previamente definido de categorías). Para crear dicho sistema introducimos parejas de X e Y conocidas para que el sistema ‘aprenda’, en un proceso denominado ‘entrenamiento’. Técnicamente el concepto de ‘aprendizaje’ corresponde a ser capaz de hacer un mapeo de X a Y con el mínimo número de errores y generalizando a entradas X que el sistema no haya visto previamente durante el proceso de entrenamiento.
Esta forma de modelar sistemas mediante aprendizaje automático se caracteriza porque el sistema aprende las reglas de forma implícita mediante ejemplos, en lugar de que tengamos que modelar explícitamente todas y cada una de las reglas. Para aplicar la Inteligencia Artificial (en su faceta de aprendizaje supervisado, que es la más usada) en una empresa hacen falta como mínimo tres ingredientes: datos etiquetados, capacidad de cómputo y equipo humano.
Los datos etiquetados
Los datos etiquetados se refieren a las parejas de entradas X con su salida esperada Y. Si usamos técnicas de aprendizaje automático convencional los datos etiquetados quedarían de forma muy similar a como se representa en el esquema que publicamos en este mismo reportaje. Por el contrario, si usamos aprendizaje profundo necesitaremos más número de datos. Por ejemplo, para problemas de imagen necesitaremos entre 10.000 y 100.000 muestras, si no usamos transferencia de aprendizaje, y del orden de centenas si podemos usar transferencia de aprendizaje.
¿Cómo se consiguen los datos? Ya hemos visto que en todos los tipos de aprendizaje supervisado los datos son el combustible necesario para entrenar modelos; cuantos más datos tengamos a nuestra disposición más prestaciones seremos capaces de obtener.

La gran mayoría de empresas disponen de muchos datos que han ido acumulando a lo largo de su historia, así que el
desafío suele ser de extracción (los datos suelen estar desperdigados en varias bases de datos inconexas) y de etiquetado (aunque dispongamos de datos de entrada al modelo -la X- no siempre disponemos de la salida esperada -la Y-). Para el etiquetado podemos recurrir a etiquetado manual usando plataformas online o desarrollar soluciones propias.
En el caso de que la empresa no disponga de datos para entrenar modelos, es necesario crear mecanismos de adquisición de datos; incluso creando nuevos productos gratuitos cuyo beneficio para la empresa es la propia obtención de datos.
‘Capacidad de cómputo’
Otro de los ingredientes necesario para el aprendizaje supervisado es la ‘Capacidad de cómputo’. Esta capacidad es relativamente baja si usamos aprendizaje automático convencional, en el que las métricas principales son las CPUs y memoria RAM (muchos modelos son paralelizables), necesitándose una capacidad muy superior si usamos aprendizaje profundo, especialmente con datos de alta dimensionalidad (imágenes, etc.), en el que es necesario disponer de hardware más especializado: GPUs (tarjetas gráficas) o TPUs (procesadores de tensores, especializados en las operaciones que se hacen en aprendizaje profundo).
¿Cómo obtener capacidad de cómputo? Podemos comprar en propiedad el hardware (en muchos casos con un ordenador con 64-128 Gbytes de RAM y varias GPUs puede resultar suficiente) o bien podemos alquilar recursos computacionales en la nube (Amazon EC2, IBM Watson, Amazon Sagemaker, Google Cloud Engine, etc.).
El equipo humano técnico
Por último, es necesario un ‘Equipo humano’, que a su vez conviene diferenciar en: técnico y no técnico. El primero es el encargado de la implementación de los algoritmos y el ciclo de vida de puesta en marcha de los modelos de Inteligencia Artificial. Aunque cada vez están surgiendo más soluciones paquetizadas en forma de librerías de programación (Pytorch, Tensorflow, Fast.ai, Keras, etc.) o servicios en la nube, estos perfiles técnicos especializados precisan conocimientos de programación (Python principalmente), sistemas (Linux o entornos de orquestación en la nube tipo Kubernetes, etc) y parte de matemáticas (especialmente cuando las cosas no funcionan a la primera).
¿Cómo creamos un equipo técnico? Hay tres posibilidades. Si la empresa ya tiene un equipo informático, podemos crear un plan de formación focalizado en Inteligencia artificial: tanto online como presencial existen multitud de recursos para la formación técnica: máster de deep learning en castellano, nano-degrees Udacity (inglés) e incluso recursos gratuitos como Fast.ai (inglés). Si la empresa no dispone de equipo técnico y considera que la IA va a ser un valor estratégico o core para su negocio entonces es recomendable crear un departamento reclutando personal ya especializado en Inteligencia Artificial (desgraciadamente estos perfiles no abundan). Si la empresa no dispone de equipo técnico, pero prevé que la implantación de la IA es puntual, hay que valorar el externalizar dicho desarrollo e implantación a una empresa especializada.
Mientras que el equipo técnico es el encargado de cómo implementar la inteligencia artificial, el equipo no técnico -compuesto por gestores de producto, mandos intermedios y ejecutivos- ha de decidir el qué, el dónde y el porqué de la implantación de la IA en el negocio considerando el impacto transversal en toda la empresa: competitividad, inversión, impacto en el balance, riesgo de ejecución, comunicación interna y externa, etc. A pesar de que el equipo no técnico no necesita saber todos los detalles de las implementaciones (programación, sistemas, etc.) es muy conveniente que tenga una formación a alto nivel sobre la Inteligencia Artificial para poder tomar las mejores decisiones respecto a la incorporación de ésta.
¿Cómo formar al equipo no técnico?
Si contamos con perfiles técnicos podemos formarlos en áreas de negocio (gestión de producto, áreas de negocio) mediante MBA o formación similar; Otra posibilidad es formar a perfiles ejecutivos y mandos intermedios en Inteligencia Artificial aplicada al negocio. Existe formación online en forma de MBAs ofrecidos por el MIT, Oxford y Berkley (inglés), nano-degree en gestión de productos IA de Udacity (inglés), curso introductorio de Andrew Ng en Coursera (inglés) y máster ejecutivo en IA (castellano) del Instituto de Inteligencia Artificial A nivel de organización es habitual que el equipo de Inteligencia Artificial sea un departamento independiente y las otras áreas de negocio sean clientes de éste.
Puesto que las mejores prácticas en lo relativo a la especificación, desarrollo, despliegue y realimentación de modelos de Inteligencia Artificial están todavía relativamente más inmaduras que sus equivalentes en el desarrollo de software convencional, es muy recomendable que los primeros proyectos en los que se embarque una empresa que quiera incorporar esta tecnología a su portfolio sean inicialmente sencillos y de bajo riesgo de ejecución (tanto en captación de datos de entrenamiento, como en desarrollo de modelos, como en despliegue).
Diferencias entre aprendizaje profundo y aprendizaje automático convencional
• El aprendizaje profundo requiere comparativamente más datos de entrenamiento que en el aprendizaje automático convencional.
• Las prestaciones del aprendizaje profundo siguen aumentando a medida que aumentamos el tamaño del conjunto de datos de aprendizaje; mientras que el aprendizaje automático convencional tiene un tope a partir del cual incluso aunque dispongamos de más datos ya no mejoran las prestaciones.
• En el aprendizaje automático convencional es necesario introducir los datos de forma estructurada y a menudo tenemos que recurrir a la extracción manual de características, proceso que requiere personal especializado muy familiarizado con el dominio del problema (típicamente con años de experiencia en un campo) mientras que en el aprendizaje profundo es factible introducir los datos con poco o nulo procesado y el propio modelo construye una representación jerárquica de características.
• Los tipos de estructuras de datos de entrada y salida son más flexibles en el aprendizaje profundo: donde podemos crear modelos cuyas entradas y salidas sean matrices (p. ej. imágenes), secuencias (textos o fragmentos de audio), grafos, conjuntos (secuencias donde el orden de los elementos no importa), etc.